July 16, 2021, by Faraz Khan
Train a Custom Computer Vision Model using Detectron2
Training a custom computer vision model to work on your research dataset may be daunting due to the imagined complexities and effort involved. However, some very powerful open-source frameworks, such as Detectron2, have recently been made available to simplify the process.
Detectron2 is an open-source framework that implements state-of-the-art computer vision algorithms. Detectron2 comes with some pre-trained models for object detection, classification, and segmentation. An intermediate level knowledge of Python is required to train a custom model.

To show the results and benefits of a custom computer vision model in research, we recently worked with a research group in the School of Pharmacy. The researchers were faced with a challenge of calculating the area of polymer spots in thousands of images, as part of their work on medical catheters. Some examples of the images containing the polymer spots can be seen (faintly) below:
|
|
|
|
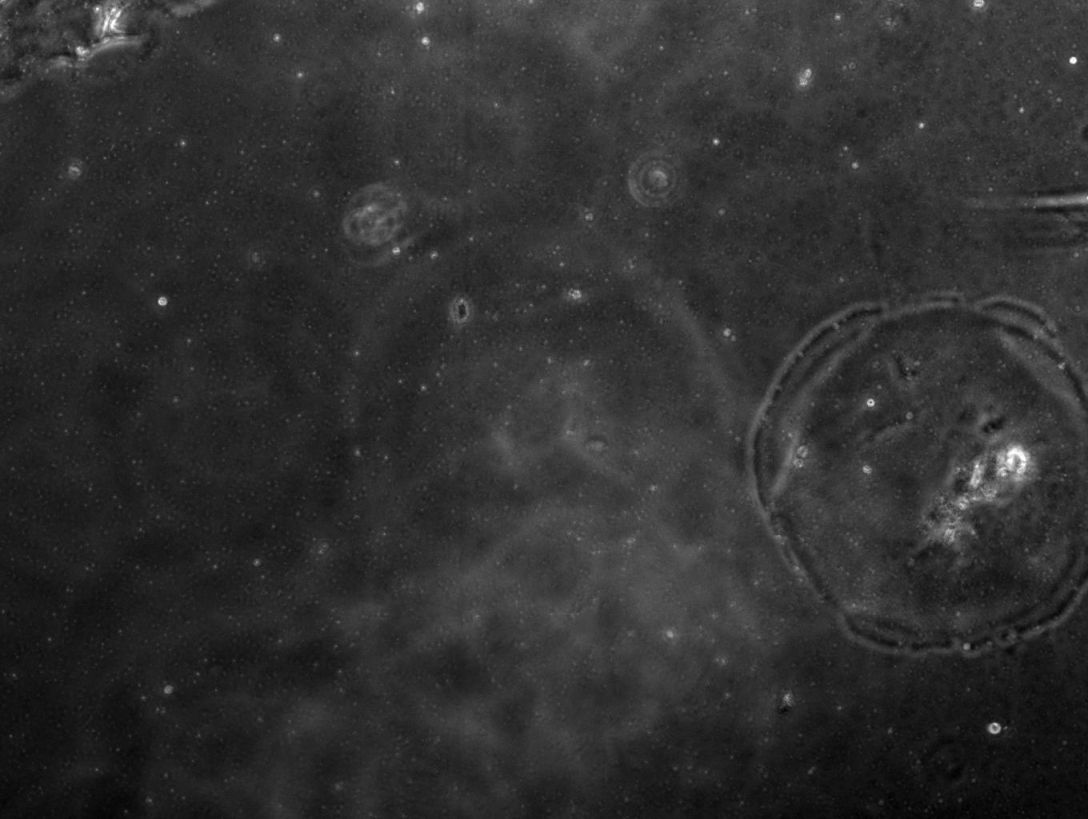


The polymer spots were being identified manually. Processing each image took about 30 seconds. Given the size of the full dataset, an automated solution was deemed preferable.
To automate the task using Detectron2 and train a custom model, a training dataset is required for the model to learn from. The training dataset ideally consists of images that vary and represent an overview of the full dataset. For the dataset shown above, 150 images were used for training. Researchers labelled the 150 training images to show exactly where each polymer spot is located. Using the images and the accompanying label data from this exercise, Detectron2 could learn to identify polymer spots in any image, including those it had never seen before.
Once the training dataset is ready and labelled, a custom model can be trained using as little as the following block of code:
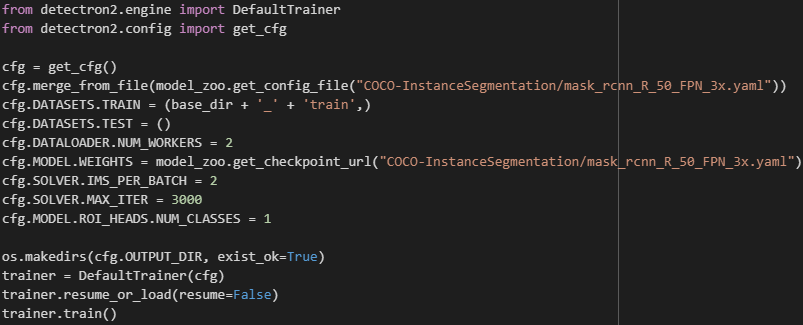
Once the model has been trained, it can identify polymer spots in any image. The following detections were made by the custom model, along with the area calculated for each spot. Using a GPU node on the University’s HPC, the researchers were able to analyse over 1000 images in less than 2 minutes. This is about 300 times faster than manually processing the images.
|
|
|
|

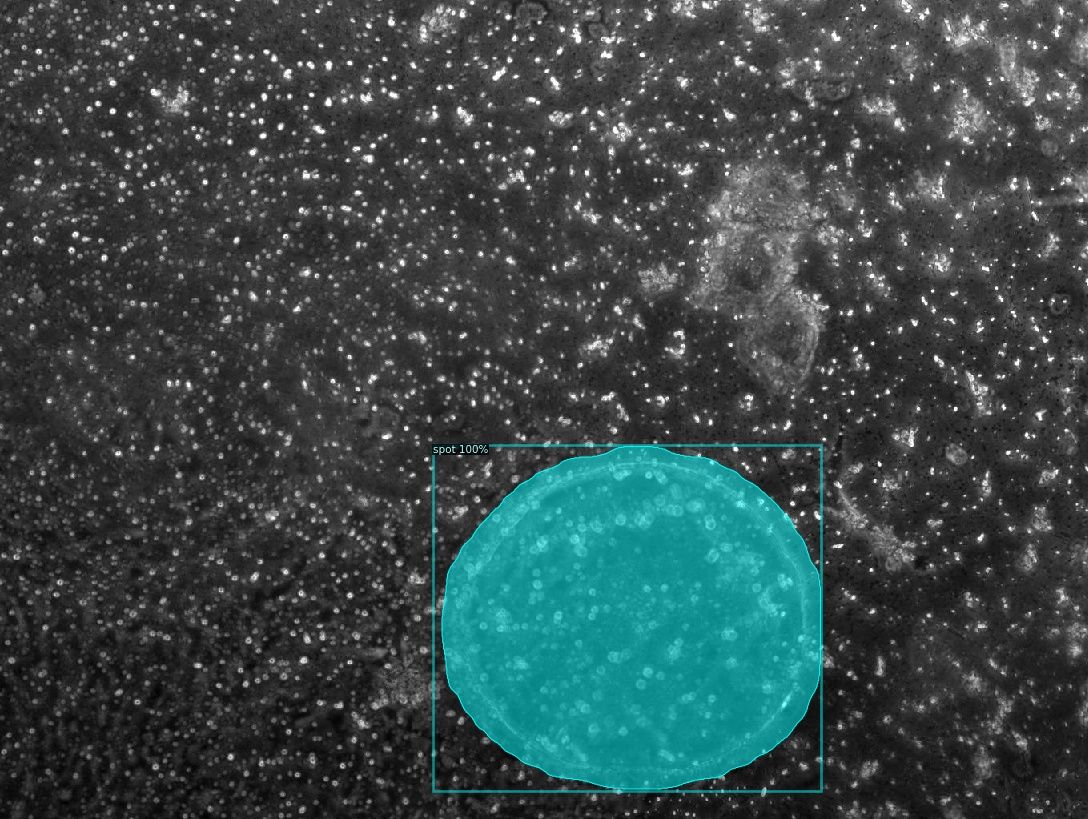

If the results shown here are of interest and you would like to train your own custom computer vision model, please get in touch with a Digital Research Specialist.
Sorry, comments are closed!