September 25, 2020, by Faraz Khan
Learn how to train a Simpsons character classifier at home using Ludwig
Researchers may be wondering what tools are available for them to work on their datasets from home. In this blog, we highlight an open-source toolkit that allows researchers to implement machine learning architectures and deep learning models on their home computers with little to no coding.
In this blog post you will learn about the capabilities of a powerful open-source, deep learning framework and how to install and use it to build a computer vision classifier.
The computer vision capabilities of this tool-kit will be explored here and demonstrated by training a deep learning system that can identify characters from The Simpsons.

Over the past decade, deep learning models have been shown to be highly effective in all tasks relating to computer vision and data science. Although deep learning systems are significantly better than their conventional machine learning counterparts, training and testing one is a fairly difficult process that requires sophisticated knowledge of advanced machine learning architectures. Deep learning systems involve a fair bit of coding for formatting and handling the input data, writing the model architecture, optimizing the hyper-parameters, evaluating the results and testing the system for deployment.
In order to make deep learning more accessible, Uber AI has released Ludwig, an open-source deep learning toolbox that is built on top of TensorFlow. Ludwig helps make deep learning easier to understand for non-experts, while also allowing faster model improvement iteration cycles for experienced developers and researchers. The toolkit achieves this by providing a set of pre-written model architectures that can be combined to form an end-to-end pipeline optimized for a specific project.
The core design principles of Ludwig are:
- No coding required: no coding skills are required to train a model and use it for obtaining predictions.
- Generality: a new data type-based approach to deep learning model design that makes the tool usable across many different use cases.
- Flexibility: experienced users have extensive control over model building and training, while newcomers will find it easy to use.
- Extensibility: easy to add new model architecture and new feature data types.
- Understandability: deep learning model internals are often considered black boxes, but we provide standard visualizations to understand their performance and compare their predictions.
Installing Ludwig
Python3 is a requirement for installing and using Ludwig. Follow this beginners guide for installing Python3 on your home computer (Windows, Mac or Linux). Once Python3 is installed on your system, Ludwig can be installed using the command:
pip install Ludwig
More detailed installation instructions can be found on their official GitHub.
Configuring Ludwig
You can train a deep learning model by simply providing two files: a .CSV file that outlines the dataset input format along with corresponding labels and a model configuration, and a .YAML file that outlines the architecture and input/output features of the model.
For training the Simpsons character identifier, I’ll be using the Simpsons Characters Dataset, which is a labelled image dataset of 20 characters from the Simpsons show composed of 400-2000 pictures of each character.

Input .CSV File
The Simpsons dataset is structured in such a way that images of each character have been added to their own respective folders. This way, the folder names represent the class labels of the images contained within them. The directory tree of the dataset is as follows:

From the above directory structure a .CSV input file for Ludwig can be automatically populated using a simple folder to csv python code using pandas.
The .CSV file can also be manually populated if the dataset size is relatively small and manageable.
Model Configuration .YAML File
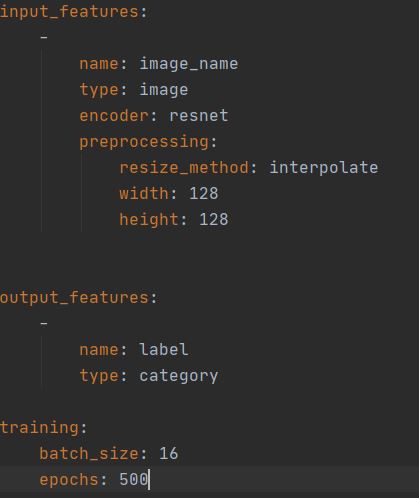
A model architecture file is a .YAML configuration file that lists the input and output features of the model along with different characteristics of the model architecture and training process. The model configuration file used for training the Simpsons character classifier is given below. Other architectures supported by Ludwig can be found from the official user guide.
Training/Testing with Ludwig
Once the .CSV input file and .YAML configuration file are ready, a network can be trained in Ludwig by typing the following command in the terminal:
ludwig train [options]
The only required arguments to this command are the locations of the .CSV and .YAML files. Other optional arguments can also be provided as explained in the official user guide. The complete command for training the Simpsons classifier would be:
ludwig train --data_csv simpsons_dataset.csv --model_definition_file model_definition.yaml
--output_directory results
Once a model is trained, it is saved in the specified output directory (by default ‘results’ is the output directory if none is specified). This model can then be used to evaluate and predict new data by typing the following command in terminal:
ludwig predict [options]
The only required arguments here are the CSV file and location of the trained model. Other optional arguments are listed in the official documentation. To test the Simpsons classifier the command would be:
ludwig test --data_csv prediction_csv.csv --model_path results\\experiment_run_1\\model
--output_directory results\\prediction
Prediction Output
The output takes the format as specified in the model architecture and is saved in a .CSV file along with the prediction probability. The predicted output labels and probabilities can be mapped to their respective images to get the predicted outputs in the below format.

|

|

|



Ludwig allows researchers to explore computer vision systems and deep learning architectures using their own datasets. Following the instructions above, Ludwig can be installed locally and your own custom computer vision classifier can be trained by providing the required input and model architecture files. As can be seen, the trained network can successfully identify the characters with a high degree of confidence.
Aside from image classification, Ludwig can be used for Natural Language Understanding, Spoken Digit Speech Recognition, Speaker Verification, Time series forecasting and Visual Question Answering.
If you are interested in the content of this blog and looking to implement automation and machine learning in your research, please get in touch with a Digital Research Specialist. We can provide advice and support.
Sorry, comments are closed!