
September 3, 2020, by Faraz Khan
An Attempt at Automatically Classifying Political Leaflets Using Ludwig
In this blog, we discuss some innovative AI-driven work being undertaken in collaboration with Prof. Caitlin Milazzo from the School of Politics and International Relations.
Ludwig is on open-source toolbox that allows the training and testing of deep learning networks without the need to write any code. In this pilot study we wanted to see if we could use Ludwig to train an image classification network on a difficult dataset.
The image dataset
The image dataset has been crowd sourced by people uploading pictures of political leaflets to a website. Metadata was also added. As the project relies on crowd-sourced data, it is fair to assume that the metadata will not always be accurate or complete. Could you train a machine-learning classifier to automatically identify features of the leaflets and thus counter-check the crowd-sourced metadata?

|

|

|



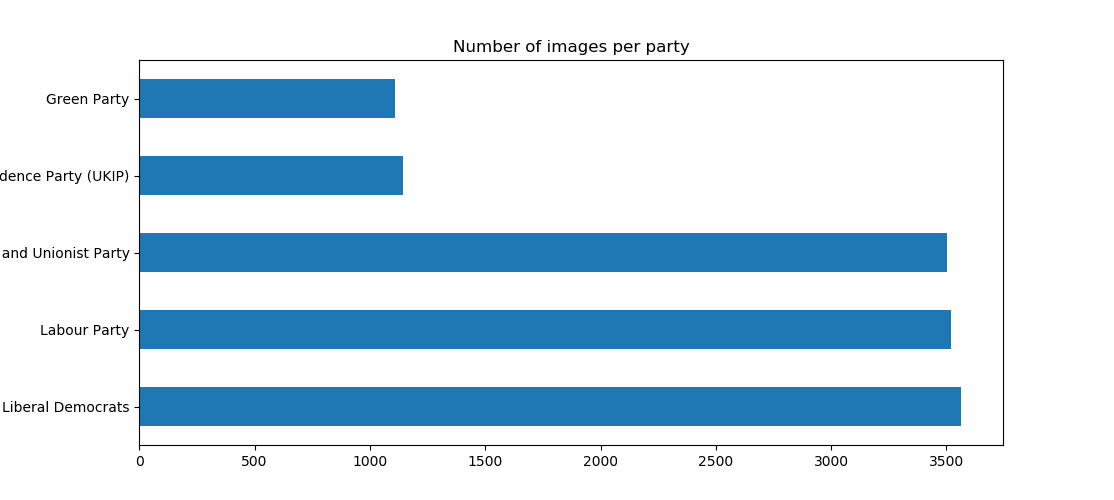
Examples of the dataset are shown above. It is not an ideal collection of images from a machine learning perspective, as there are major variations in lighting, angle, and clarity of the pictures. The dataset was also not very balanced. There were a total of 171 unique classes (here, political parties), but a majority of the classes had only a single representative leaflet. Some Exploratory Data Analysis (EDA) showed that a majority of the images belonged to five political parties: the Liberal Democrats (3565 images), the Labour Party (3519 image), the Conservative and Unionist Party (3502 images), the UK Independence Party (UKIP) (1144 images), and the Green Party (1111 images).
Data augmentation:
To further increase the number of image and to add some variation, the images were augmented using an augmentor pipeline that performed the following augmentations with varying degree of probabilities: rotate90, rotate270, flip_left_right, flip_top_bottom. Augmenting the images helps to generalise the trained classifier by bringing variation to the original dataset. It also helps with training the classifier by increasing the number of training images.

|

|

|



Training the classifier with Ludwig
To train the image classifier, a ResNet-152 network was used with basic image pre-processing. The ResNet model architecture can be seen in the image below:
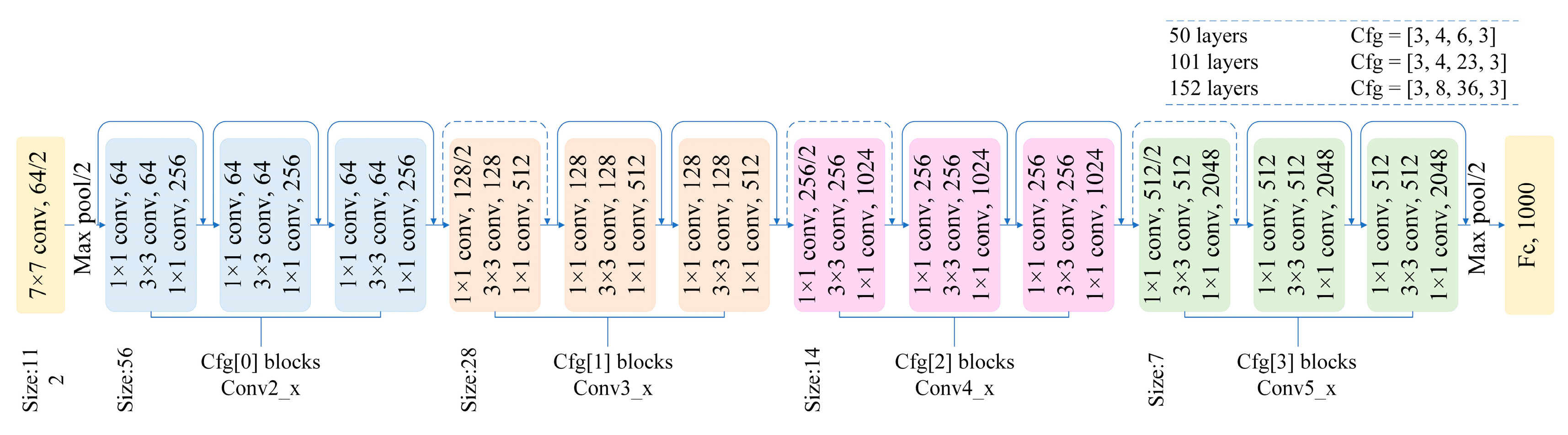
Image reference: https://www.mdpi.com/2076-3417/10/7/2528/htm
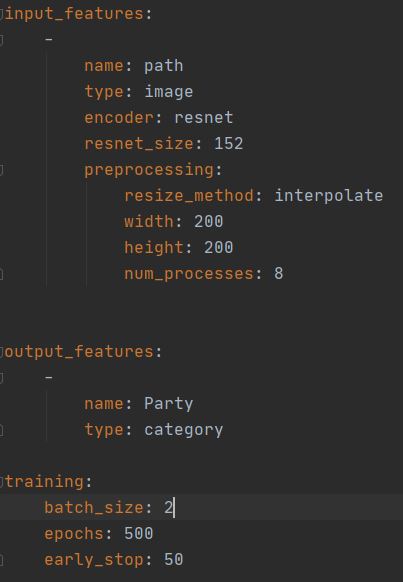
Training the ResNet network is easy in Ludwig. We had only to include the following parameters for our model architecture file:
Results:
After training, the classifier was capable of predicting the leaflet images with an overall accuracy of 74%, which is impressive given how varied the dataset is. This result was achieved with minimal pre-processing. This is an on-going study and attempts are now being made to further improve the accuracy of the classifier.
Future work and improvements:
To improve the results and to add further functionality to the trained network, we are working on adding additional steps to the machine learning pipeline. Since Ludwig already has some powerful Natural Language Processing (NLP) networks built in, there are plans to include an OCR element that would extract text from the images. This textual data will then be used to train an additional network within Ludwig to provide additional insights and complement the results from the image classification network.
If you would like to learn more about Ludwig and how it might be used in your research, please attend our drop-in webinar on the 14th of September at 2pm. Details and a link to the event can be found here: https://uniofnottm.sharepoint.com/sites/DigitalResearch/SitePages/Digital-Research-webinars.aspx
Sorry, comments are closed!