April 17, 2023, by Sarah Colborne
Documenting the pandemic and beyond: website captures for the University Archives available to view
This is a post by Laura Peaurt, Digital Preservation Officer and Sarah Colborne, Archivist (Collections).
Capture and Preservation
In a previous blog we discussed using Preservica, our digital preservation platform, to successfully capture websites and social media for the archive. This is known as web archiving.
The tools provided by the platform allow us to continue to successfully archive and preserve the university’s publications and communications platforms in the digital space. This means the websites we have captured over the last three years, and continue to collect, can be accessed and experienced by future generations of researchers in the same way they are viewed today.
Website capture was a new area of collecting for us at the start of the pandemic, and we were unsure of how successfully it would work in practice and how much work might be involved.
The first use of these web archiving tools gave us the ability to digitally document part of the University’s research role and community experience of the challenges and difficulties of the Covid-19 pandemic. They enabled us to capture blog posts, press releases and news stories as they unfolded.
We had to consider and define our collecting scope to keep the workload manageable whilst ensuring we captured a good representation of the University’s website. We reached out to the University community to ask for suggestions for what we should capture.
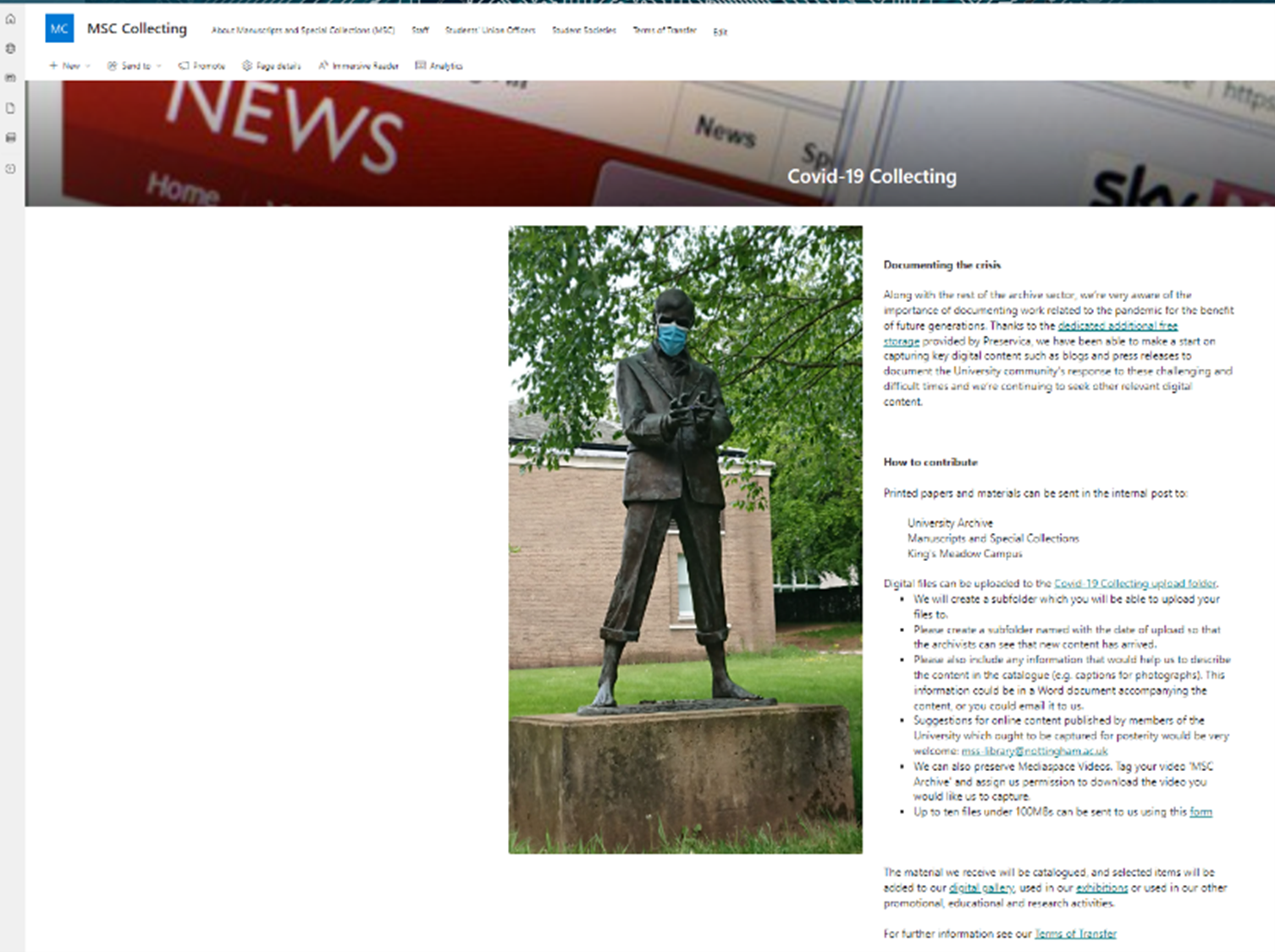
Sharepoint site requesting suggestions from University members to help with documenting the University community’s response to the pandemic
Crawling websites can be challenging as the complex structure of webpages with many different interactive elements can be difficult for crawling tools to capture. As well as Preservica’s own in built tool based on Heritrix, we also use other tools to support this work including Conifer, archiveweb.page and Browsertrix.
We archive our website captures in the WARC file format, the internationally recognised standard for capturing websites for archiving purposes.
Over the last three years we have developed criteria for capture and established a set of websites and digital publications that we continue to regularly capture automatically and systematically.
Regular captures have included the University’s homepage, its coronavirus information pages and its research response. We also regularly collect the blog posts of prominent university figures including the Vice Chancellor as well as news articles (such as Campus News) and other forms of digital communications produced by the University. More recently we started capturing a selection of university twitter accounts.
Accessing our web archives
In Discovering the Digital blog in November, we described the development of our Universal Access portal which allows researchers to navigate and view the born digital collections we hold. This includes the ability to browse through our archived website captures like viewing a live site.
We have now pleased to have launched this portal via a dedicated digital workstation in the Manuscripts and Special Collections reading room at Kings Meadow Campus. Visitors to the reading room can access our publicly available born digital resources alongside the rest of our paper and digital collections. This includes some of the web captures made during the Covid-19 pandemic. More digital captures will be made available as we continue to catalogue them.
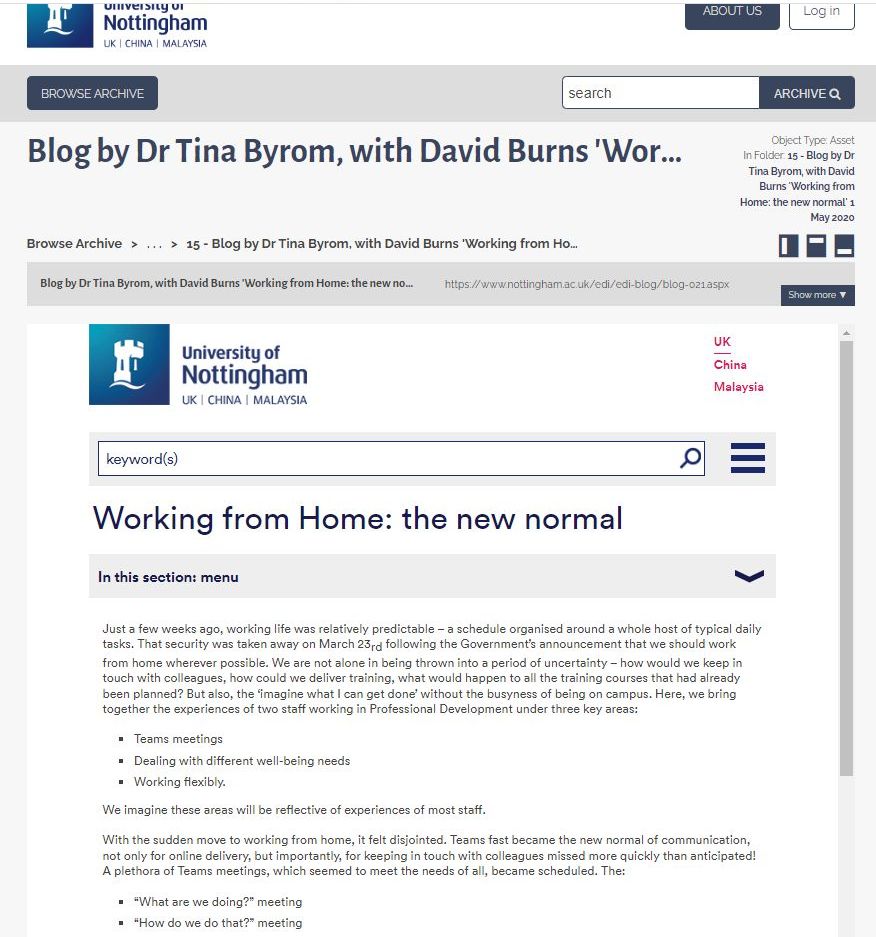
Blog post by Dr Tina Byrom, with David Burns ‘Working from Home: the new normal’ 1 May 2020 UL/E/5/5/15
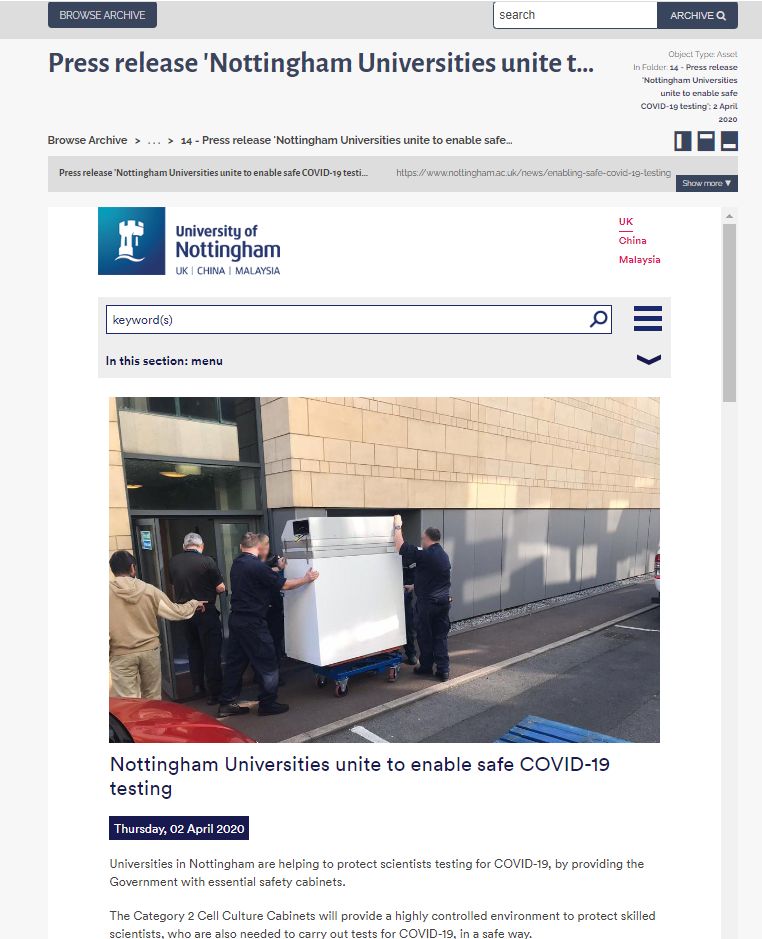
Press release ‘Nottingham Universities unite to enable safe COVID-19 testing’; 2 April 2020 UL/E/5/5/14
Descriptions of the captures can be seen in our Manuscripts online catalogue, some links are provided below. To view the web captures themselves, please make an appointment to visit us. We will continue to update as we make more collections available in the future.
- Materials gathered following an appeal organised by the Communications and Advocacy Team. UL/E/5/6/3
- Webpages, blog posts and news articles about the Covid-19 coronavirus pandemic UL/E/5/5
- UNNC coronavirus coverage; 2020-2022 UL/E/5/3
- UNMC coronavirus coverage UL/E/5/4

Website and video ‘Student services welcome – extraordinary is what you make it’ UL/E/5/5/25
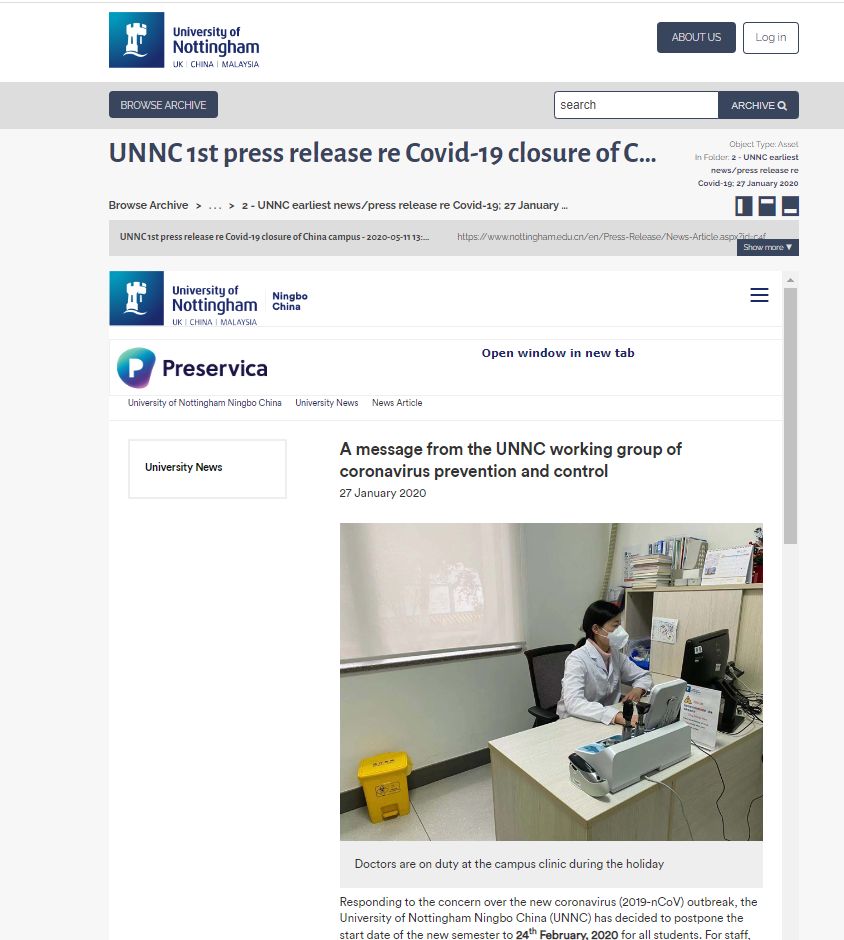
Press release UNNC earliest news/press release re Covid-19; 27 January 2020 UL/E/5/3/2
We will continue to archive university and other websites and would welcome your suggestions of content which could be important to capture for the archives. More information about our work is available from our website, magazine or social media @mssUniNott.
No comments yet, fill out a comment to be the first





Leave a Reply