
June 10, 2020, by H Cotterill
But what do you do all day? – Our second lockdown diary
This is the second of our lockdown diaries, looking at the work that staff in Manuscripts and Special Collections have been doing since we switched to home-working.
In last week’s blog the focus was on cataloguing; this week I want to look at some of the behind-the-scenes work that we’ve been doing to improve the discoverability of our images and library books, document the physical state of our collections, and find out just how much space we have left in our archive and special collections store.
Metadata
We digitise hundreds of items a year from our collections – sometimes a single page from a document or a book, at other times an entire multi-page document – and these images are stored in our digital asset management software, Portfolio. Items may be digitised as part of customer orders, for our exhibition programme, or to create surrogates when the original item is too fragile to be handled. In order for staff to easily find an image from amongst the thousands that we have, we then need to add descriptive metadata.
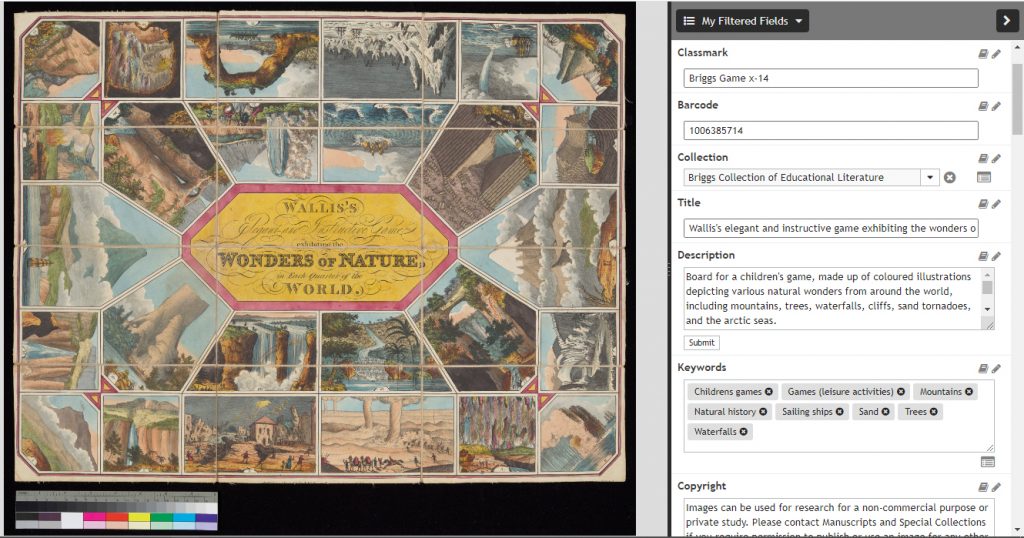
Example of an image with descriptive metadata
To put it simply, metadata is data about data. Descriptive metadata relates to a piece of information such as a photograph, and gives information about it such as a title. We have a substantial backlog of digitised images that need metadata adding, and it is one of those jobs that you can do from home without needing access to the physical item. Since the start of lockdown staff have been working through the backlog. This includes recording the reference of the item or book an image is from, as well as noting the type of document it is (e.g., letter, poem, photograph, map, etc.), and a description of the content. Perhaps the image shows a particular person, place, or building. Maybe there are animals in the image, or people wearing specific clothing. If we do this correctly and in enough detail, then for future projects we can search based on a keyword and find all of the digitised images from our collections that fit that keyword.
Whilst this is useful for staff it also has a benefit for our customers, because when we select images to feature in our digital galleries, the descriptive metadata is already there and ready for users to also search and find appropriate images for their research.
Correcting library classmarks
When UoN Libraries switched to a new Library Management System back in April 2019, a lot of work was done to ensure that book records transferred correctly, and although most errors were caught and corrected straight away, a small percentage remained. Working from home has provided an opportunity for us to focus on correcting all of the titles on the spreadsheet of known errors, meaning that the library catalogue NUsearch will now show correct classmark information for the books we have in our special collections. This is vital if we are to match a customer request with the correct book and we aim to have all of the known errors corrected by the end of the month.
Conservation

An example of our hard-copy conservation records.
Now conservation really is one of those tasks that it is impossible to do remotely. With no access to the original documents or books, all repair and repackaging work has come to a halt, but this has given our two conservation staff time to do one of their favourite things – catch up on their paperwork.
As mentioned in our previous lockdown diary one of the things that we’ve achieved during lockdown is testing the upgrade to our archive management software, CALM. We have decided to make better use of the Conservation database within CALM, and use it as a place to store information about cleaning, conservation and preservation work carried out on documents and books by our staff and volunteers over the past twenty years.
Our preservation assistant, Emma, has been working through the historic conservation data handwritten on paper documentation sheets. She has been transferring this information into a spreadsheet and has inserted over 5,000 entries so far with plenty more still to do. This is what she’s said about the work that she’s been doing, “It is important that we document conservation treatments on our collections, and this should be accessible forever so that in future we (or other conservators) can see what treatments have been carried out. This kind of information helps if further treatments are required, as we can then establish what chemicals and treatments are suitable to use. It is also useful to help assess how well a treatment has acted over time.
We wouldn’t normally have time for data entry work whilst working on preserving the physical objects in the archive, but whilst practical work is on hold for the time being it has given me the opportunity to enter this important information. Once all the data is in a digital format on the spreadsheet it will be transferred onto CALM and will be beneficial in creating a better understanding about the collections and what has been done to them”.
Space Management

Photograph of the Manuscripts and Special Collections store
The final piece of work to tell you about in this blog is our space management project. We need to know how much space we are currently using in our archives and rare books store, and how much space is left and is available for new acquisitions of material. There are areas of the store where we know that a different shelf arrangement could be beneficial in terms of space management. Some printed books have also recently been moved to lie horizontally rather than vertically, as we know that this is better for their long-term preservation. Our current shelf diagrams are therefore out of date.
We won’t be able to do the final survey of the store until we are back at King’s Meadow Campus, but we’re getting a head start on the work by creating a new spreadsheet in which every shelf is assigned a maximum capacity. The spreadsheet includes built-in formulae so that when a member of staff types in the number of boxes on a shelf or the percentage of shelf currently in use, it will automatically calculate how much space is left. We have enough information available in our current documentation to be able to fill in most of the spreadsheet from home.
Coming up next
Keep an eye on our blog for further updates on what we’ve been working on over the past few months. Next week’s blog will focus on the work of the newest members of Manuscripts and Special Collections – the staff of the University Museum.
No comments yet, fill out a comment to be the first





Leave a Reply